< Basic >
用歷史發生順序的角度來理解,我覺得挺好的。
先備知識:
電腦無法儲存那些我們人類識別的出來的東西,像是文字(letters), 數字(numbers), 圖片(pictures), 電腦完去無法儲存,電腦從始至終只能儲存bit並且拿來運作,而這個 bit 只會有兩種 value, true or false, 1 or 0, yes or no, 或是任何你認為可以代表這兩種值的名詞。並且電腦是通過「電」來運作,如果把「電」實體化(這裡只是我自己的比喻,專家請不要太認真,我只想幫助自己好理解電腦運作), 實際上「真正的 bit」就好像那些電碎片,時而出現,時而消失。而通常在電腦科學領域,我們常方便性的使用 1 和 0 去表現。所以一樣的編碼也是電腦科學領域,我們會常在文章裡看到 1 和 0。
要認知的 2 件事實:
- 電腦最早是美國那裡發明的,所以當然一開始就只針對英語字母做設定
- 但軟體後來不是只有英語母語者在使用,而是世界上所有不同母語的人們做使用
那後來是怎麼做的..? 這裡就是重點
幾個名詞解釋:
-
encode: (verb) convert into a coded form.
-
code: (noun) a system of words, letters, figures, or other symbols substituted for other words, letters, etc.
-
character set, charset: The set of characters that can be encoded. 實際上常用在同義於 "字符集"
-
code page: A "page" of codes that map a character to a number or bit sequence. A.k.a. "the table". 實際上常用在同義於 "字符集"
-
string: A string is a bunch of items strung together. A bit string is a bunch of bits, like
01010011. A character string is a bunch of characters, likeHi, there. 在幾個情況會出現的同義為 "字串/符號/字符/sequence". -
假設目前有十進位數字 99,在不同進位下會長不一樣,但實際上是同一個東西。
- Binary(二進位):
1100011in binary - Octal(八進位):
143in octal - Decimal(十進位):
99in decimal - Hexadecimal(十六進位):
63in hexadecimal
- Binary(二進位):
16進位補充:
|
|
< 理解方向與順序 >
名詞似乎有點混亂:
應當從電腦科學的基本講起,當涉及到編碼我們必須了解字符集與編碼是兩件事。
在討論編碼時,我們可以拆成:
- 字符集(字元表/字元庫/字元列表/Character set/Charset/Character repertoire)
- 編碼(編碼方式/儲存方案/Encoding/Character encoding)
從這兩個面向去理解會比較清楚。
那這是什麼意思呢?
總體來說就是字符編碼(Character encoding)這件事我們要先知道今天是使用哪個字符集(想像成某種表)(Charset)去讓我們的符號對應表上定義的數字,然後我們再選用哪種編碼方案(Encoding)把表上對應到的數字透過當前編碼方案去儲存到電腦中。
討論順序:
- 不去探討久遠的 EBCDIC
- ASCII 的出現
- Unicode 的出現
- UCS-2, UCS-4
- UTF-8, UTF-16
< ASCII 的出現 >
「ASCII」(American Standard Code for Information Interchange),我覺得要了解編碼,大概可以從這裡開始。
因為要讓電腦儲存並處理文字,所以最早美國出現 ASCII 來解決。
1. 先討論字符集:
所謂字符集,就好像是用另一種形式呈現同樣的東西,在編碼裡我們常把符號對應到特定數字去代表這個符號,而在 ASCII 的字符集很直覺的把文字轉換成人類日常生活理解的十進位數字。舉例: "A" 變成十進位數字 65, 把 "B" 變成十進位數字 66, 把 "a" 變成十進位數字 97,把 "z" 變成十進位數字 122,而其實這樣的對應方式就像是有一張表,在表上清楚寫明所有文字對應的十進位數字是什麼,同時這個十進位數字稱作它的碼位(碼點)(像是一種編號),也可以稱作「ASCII Code」(有些是寫以二進位表示時是 ASCII Code)。
在 ASCII 有兩種版本:
- 第一種版本
ASCII: 從十進位數字 0 - 127,總共 128 個 - 第二種版本
EASCII: 從原本的 0 - 127, 往後再加 128 - 255,總共 256 個
-
裡面的十進位數字內容大概像這樣:
- 控制字符: 0 - 31 和 127
- 可顯示字符(一些常用符號,包括數字符號0到9(非真正十進位數字,因為如果是十進位數字 0 到 9,就不用討論編碼了,直接轉成二進位即可,這邊是圖案文字的 0 到 9)): 32 - 64
- 可顯示字符(大寫英文字母 A - Z): 65 - 90
- 可顯示字符(一些符號): 91 - 96
- 可顯示字符(小寫英文字母 a - z): 97 - 122
- 可顯示字符(一些符號): 123 - 126
-
再來是追加了後面的第二種版本也稱作
EASCII(Extended ASCII):- 擴充字符集(Extended Character Set)追加了一些擴充符號: 128 - 255
這邊也許會很混亂
ASCII Code到底指的是上面說的十進位數字,還是以二進位表示也是 ASCII Code,還是以十六進位表示才算是 ASCII Code, 我覺得這邊只要理解都是同樣的東西,只是表示不同,舉個例子:
- 字符
A依照 ASCII 的字符集:- 在2進位會是:
01000001 - 在10進位會是:
65 - 在16進位會是:
41 - 在 HTML 10進位的 Entity Number 會是:
A-> 試著在 charset=UTF-8 (UTF-8 涵蓋 ASCII,後面會說到)的 html page render<p>A</p>你會發現會顯示 A - 在 HTML 16進位的 Entity Number 會是:
A-> 也可以試試<p>A</p>,也可以顯示 A
- 在2進位會是:
參考這個截圖會了解:
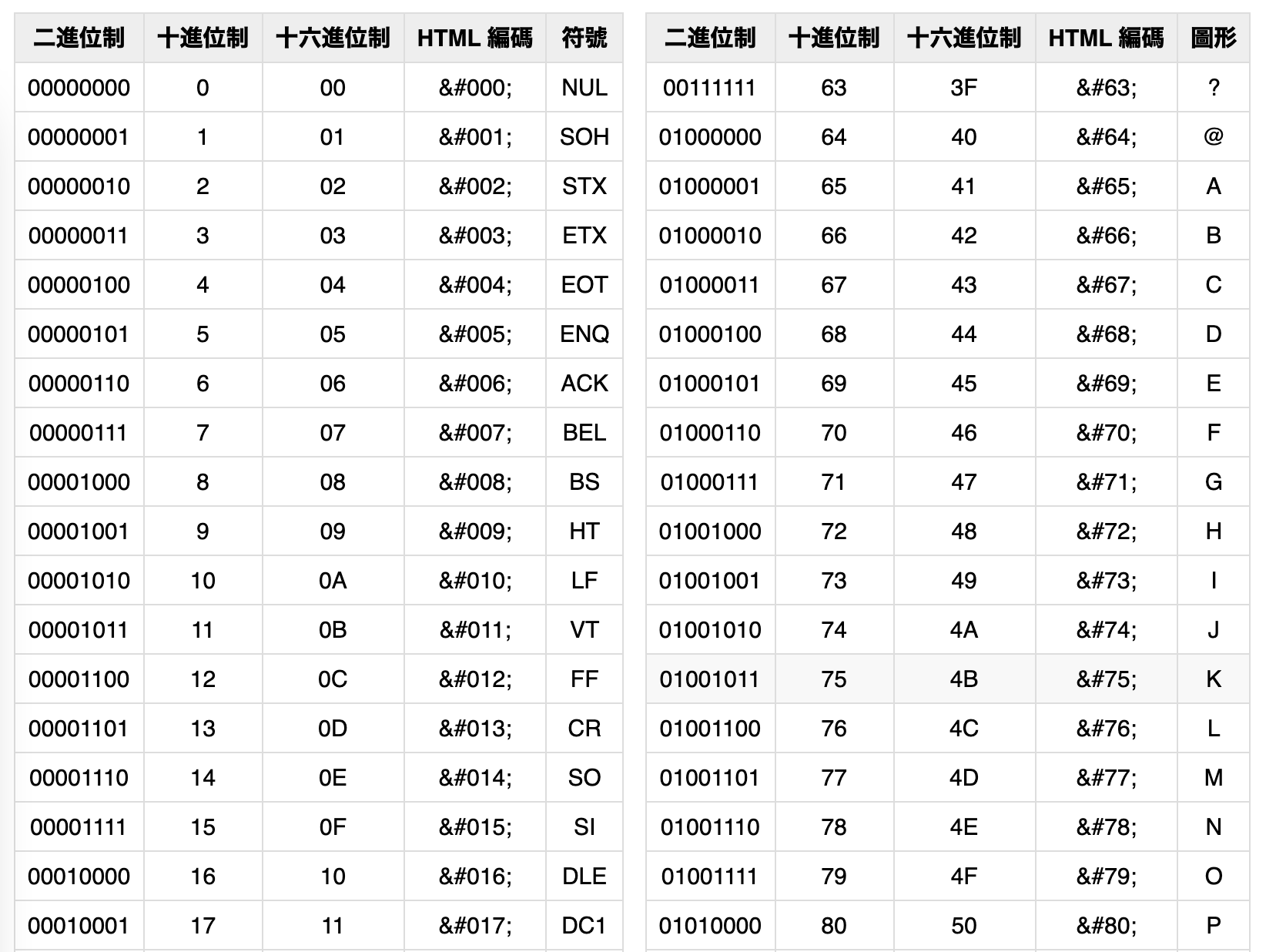
所以只是表示的問題,有時候當聽到 「A 是 65 」精確一點要說,A 在 ASCII 的規則下以十進位表示時是 65, 記得在不同進制下表示就會不一樣。
2. 再來是編碼方式:
ASCII的編碼方式很簡單,直接把對應的十進位數字轉成二進位交給電腦儲存與處理。 邏輯就像是:
- A : ASCII Code(Decimal)
65=> Binary01000001 - B : ASCII Code(Decimal)
66=> Binary01000010 - a : ASCII Code(Decimal)
97=> Binary01100001
所以基本 128 個的 ASCII Code 對應的二進位範圍會是:
0000 0000 ~ 0111 1111 : 可以發現只使用到 7 bits,左邊第一個一定是 0
擴充款的需要 256 個 ASCII Code 才會讓左邊第 8 bit 為 1。
3. ASCII 小總結:
ASCII 是什麼?
Answer: 一個早期出現的編碼規則(包括定義字符集與定義編碼方式),有一張表定義了符號如何轉換成十進位,基本款是 ASCII Code: 0 - 127,共 128 個符號而已,而編碼方式是把十進位直接轉成二進位最多就只需要 1 byte 去儲存在電腦。
特徵:
- 字符集: 有定義字符集(編碼表),讓每個符號有對應的 ASCII Code(十進位數字), 128個 或 256個。
- 編碼方式: 把 ASCII Code(十進位數字) 直接轉成二進位儲存,範圍是 7 bits 或 8 bits。
- 缺點: 支援符號非常有限,只能 Cover 到英語系字母。
- ASCII 是一個同時定義字符集,也定義編碼方式的編碼系統 (之所以這樣說是因為你會發現對於 Unicode 的實踐,後期的 Unicode 就偏向只是字符集,它必須搭配其他編碼方式,我們常用的 UTF-8 就是其中一種編碼方式,後面會說到)。
References:
- http://sticksandstones.kstrom.com/appen.html
- https://baike.baidu.com/item/ASCII/309296
- https://zh.wikipedia.org/wiki/ASCII
- https://www.wibibi.com/info.php?tid=ASCII_Code_Table
- https://dev.w3.org/html5/html-author/charref
- https://www.itread01.com/content/1549477827.html
< Unicode 的出現 >
之所以出現,是經過對 ASCII 的理解,會發現他能支援的符號非常有限,於是後來每個國家都開始對 ASCII 做擴充去支援自己語系,或是設計自己語系的編碼方式,這時候世界就有數不清的不同編碼方式,發生了一個問題那就是當網路愈來愈普及,資訊交流愈來愈頻繁,不同的編碼方式,會造成許多資料轉換的時間成本,溝通成本變高,於是 Unicode 就出現了,他幾乎把全世界的符號都包含進去,它定義了字符集(Character set), 但編碼方式卻有很多種,這個是要釐清的地方,所以當我們說 Unicode編碼,必須要知道我用的是 Unicode 字符集,但編碼方式必須再問清楚是用哪一套編碼方式去處理 Unicode?
在 Unicode 被廣泛使用之前,一開始是有兩個組織在試著建立全世界統一的字符集,分別是「國際標準化組織(ISO)出的
ISO 10646和 「Unicode Consortium」出的Unicode,後來他們也有合作把兩者合併造就現在的Unicode, 而ISO 10646還是有單獨存在的,只是後來Unicode比較被廣泛應用。
0. Unicode 字符集:
在 Unicode 字符集裡,所以符號都可以對應的一個特定數字,這個數字稱為碼點(碼位)(Code Point),這跟 ASCII 的 ASCII Code 是同一個概念,只是他們規則不同,在 ASCII 只有 128 個符號要處理,可以直接對應一個約定好的十進位數字就好,但是在 Unicode 因為需要處理全世界所有符號,它的做法是先把它分為17個平面(plane)(就很像上學分班(分群)的概念),每個平面包含 65536 個碼點(code point),所有整個 17 個平面的碼點(至今為止有定義的範圍)表示為:
U+xx0000 ~ U+xxFFFF ,其中 xx 表示16進制值從 00₁₆ - 10₁₆,共 17 個平面。
1. Unicode 是單純字符集,還是也包含編碼規則?
有些人覺得它只是字符集,有些人覺得它也包含對應的編碼規則,以我的理解, Unicode 後來因為 UTF-8 和 UTF-16 的出現(後面會提到),就比較像是一個字符集,只是在最一開始的時候的確比較像字符集與編碼規則一起(UCS-2, UCS-4 的話),它的編碼規則的確就像是 ASCII 的編碼規則一樣簡單,直接把對應的 code point(16進位)轉成2進位存到電腦裡,這也就是最一開始的編碼規則 UCS-2(由 ISO 提出),它的轉換方式是把 code point 都轉成 2 bytes,它涵蓋了 65536 個字符,也是後面會提到的 Unicode 的第一平面(BMP)。
但 UCS-2 的 code point 為 U+0000 ~ U+FFFF,共涵蓋 65536 個字符,發現所囊括的字符太少,於是乎後來又有 UCS-4,它的規則就是 code point 一定轉成 4 bytes,這時候也會發現不是每個字都要用到 4 bytes(原本英文字母在 ASCII 用 1 byte 用得好好的), 所以這個編碼規則也挺浪費的,所以之後也出現其他種編碼方式,底下講一下各個實現 Unicode 的編碼方式。
2. 實踐 Unicode編碼 常見出現形式:
- 以 U+開頭,後面接 16進位 4碼Code Point, 或 6碼Code Point
- 以 0x開頭, 後面接 16進位 4碼Code Point, 或 6碼Code Point
- 以 \x開頭,後面接 16進位 2碼Code Point,並多個連續出現,一個
\x通常就代表是 1 byte
3. 實現 Unicode 字符集的編碼方式/儲存方式
UCS-2:
- 屬於固定長的編碼格式
- 編碼範圍:
`U+0000` ~ `U+FFFF`
- 等於是字符集與編碼合在一起:
- 字符集: 這時候 Unicode字符集 就是只有 65536 個,
U+0000~U+FFFF - 編碼方式: 這時候的編碼方式也是直接
U+xxxx, 直接轉二進制儲存
- 字符集: 這時候 Unicode字符集 就是只有 65536 個,
UCS-2 相對於其它編碼方式算是最早期實現 Unicode 的編碼方式。
ISO 出的 2 bytes 編碼方式,可以編 65536 個大部分世界常用的字符,他不能包含完整的 Unicode 字符集,也因此後來出現了 UTF-16,它涵蓋了 UCS-2 可以處理的 Unicode 第一平面(Basic Multilingual Plane,簡稱 BMP) 的 65536 個 code point,但同時也支援其他平面的編碼(Supplementary Planes),所以可以說 UTF-16 可以完整支援 Unicode 所有碼點的編碼。
UCS-4:
- 屬於固定長的編碼格式
- 編碼範圍:
`U+00000000` ~ `U+7FFFFFFF`
- 等於是字符集與編碼合在一起:
- 字符集: 這時候 Unicode字符集就是它定義的
U+00000000~U+7FFFFFFF - 編碼方式: 這時候的編碼方式也是直接
U+xxxxxxxx, 直接轉二進制儲存
- 字符集: 這時候 Unicode字符集就是它定義的
因為 UCS-2 只包含第一平面,有所不足而出現。
ISO 出的 4 bytes 編碼方式, 從 U+00000000 ~ U+7FFFFFFF,可以編 20多億個字符,但後來發現實際使用範圍不會超過 U+10FFFF,所以後面 UTF-32 出現了,它就只會到 U+0010FFFF ,所以可以說 UTF-32 是 UCS-4 的子集,
UTF-16:
- 屬於可變長的編碼格式 如上面所說,它涵蓋 UCS-2 的 2 bytes 編碼方式,但也支援其餘平面的編碼,所以 UTF-16 的編碼範圍是 2 bytes 或 4 bytes。
2 bytes 時直接轉轉二進位, 4 bytes 時需像 UTF-8 一樣做編碼轉換:
- 規則1. 2 bytes 時直接轉二進位 0x0000 0000 - 0x0000 FFFF xxxxxxxx xxxxxxxx
- 規則2. 4 bytes 時要經過再次編碼 0x0001 0000 - 0x0010 FFFF 110110xx xxxxxxxx 110111xx xxxxxxxx
UTF-32:
- 屬於固定長的編碼格式 如上面所說,它是 UCS-4 的子集,也就是說它也能涵蓋所有 Unicode 的編碼,但是它的編碼範圍永遠使用 4 bytes,規則就是直接把碼位轉成二進位,不足 4 bytes, 就補滿 0 就對了
xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx
ex: A -> U+0041 以 UTF-32 來說就是 0000 0041 轉成二進位就是 1000001
那 UTF-32 下,就會以下面這個形式存進去電腦
00000000 00000000 00000000 01000001
UTF-8:
- 屬於可變長的編碼格式 之所以出現,你會發現 UCS-2 支援不足; UCS-4 和 UTF-32 都固定需要 4 bytes 太浪費了; UTF-16 最少也需要 2 bytes,會發現這些編碼對於原本就只需要 1 byte 的 ASCII 編碼的人們而言太浪費空間了,所以 UTF-8 出現了,它兼容 ASCII 的編碼,屬於 ASCII 的編碼就照舊使用 1 byte,超過再來使用 2 bytes 到 4 bytes,所以 UTF-8 的編碼範圍從 1 byte - 4 bytes
UTF-8 第一個規則: 對於碼點轉換成二進位後只有 1 byte 的符號,編碼方式與 ASCII 一樣
UTF-8 第二個規則: 對於 n bytes 的符號(n > 1),第1個 byte 的前 n 位都設為 1, 第 n + 1 位設為 0,後面 byte 的前兩位一律都設為 10,最後再把沒有補上的 bit 由碼點轉換後的二進位由最右邊依序補上。
對應的四個區間如下,基本 UTF-8 會把 code point(16進制) 以 4 bytes(UCS-4, UTF-32 的方式)去看然後來轉換達到伸縮自如的 1 byte - 4 bytes 的彈性空間:
碼點: 0000 0000 ~ 0000 007F
-> 轉換後為 1 byte,所以會是 0xxxxxxx
碼點: 0000 0080 ~ 0000 07FF
-> 轉換後為 2 bytes,所以會是 110xxxxx 10xxxxxx
碼點: 0000 0800 ~ 0000 FFFF
-> 轉換後為 3 bytes,所以會是 1110xxxx 10xxxxxx 10xxxxxx
碼點: 0001 0000 ~ 0010 FFFF
-> 轉換後為 4 bytes,所以會是 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
可能還有點模糊:直接給一個中文字的 UTF-8 舉例
- 記得 UTF, UCS 都是在 Unicode 的基礎上
- 都用
\u,U+,0x,\x, 搭配 16 進位
ex:
王的 code point 是 0x0000 738B- 轉成二進制是:
0000 0000 0000 0000 0111 0011 1000 1011 - 並且發現
王的 code point 是在第三區間0000 0800 ~ 0000 FFFF - 於是寫下第三區間的編碼樣式
1110xxxx 10xxxxxx 10xxxxxx - 接著把 step.2 的二進制形式與 step.4 的第三區間編碼樣式融合,填滿叉叉,從右到左
- 最後結果為
1110 0111 1000 1110 1000 1011 - 轉成16進制看一下(通常在寫程式都會看到
\x開頭的16進制表示),0xe7 0x8e 0x8b
|
|

我的姓氏 "林" 的話就會是這樣:

< The End >
總節:
-
編碼方式都是不經過再次編碼處理,直接從 Code Point 轉成二進位的有:
- ASCII
- UCS-2
- UCS-4
- UTF-16 在 2bytes 的時候
- UTF-32 (不夠會補滿到 4 bytes)
-
會經過判斷再次編碼調整的有:
- UTF-8
- UTF-16 在 4bytes 的時候
-
UCS(Universal Character Set), UTF(Unicode/UCS Transformation Format),兩者其實都是在實踐 Unicode,UCS 的概念其實偏像字符集,因為UCS的編碼就只是直接轉二進位,但廣義來說,也都是一種編碼方式,所以在這篇我都是歸在編碼方式,字符集就維持一種 Unicode,比較細的可以自行研究。
-
UTF-8 在 2021 年的現在非常常見,因為它是可變長度也無痛兼容 ASCII。
-
中文在 UTF-8 編碼下需要 3 bytes,所以有時看到三個連續
\x** \x** \x**這樣的東西,就可以很快的警覺有可能是處理資料時有中文字! -
而相對來說繁體中文的
Big5編碼只需要 2 bytes, 中國的GB編碼也只需要 2 bytes
補充細節可以自行研究:
- BOM(Byte Order Mark)讓編碼方式可以細分為:
- UTF-32BE
- UTF-32LE
- UTF-16BE
- UTF-16LE
- UTF-8 No BOM
- UTF-8 with BOM
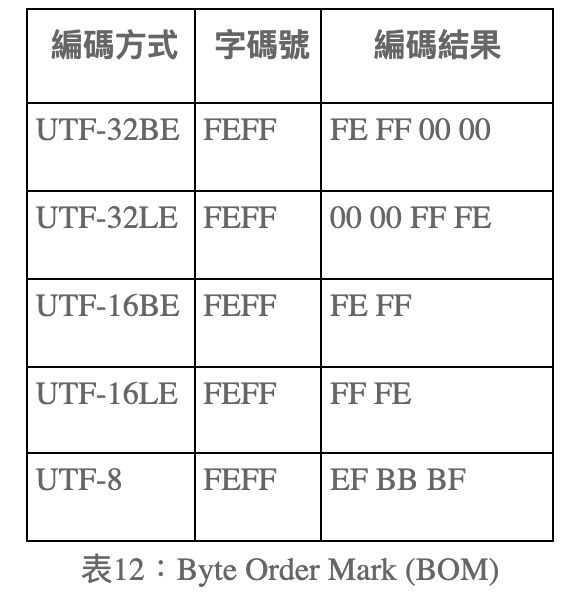
- UTF-16 在 4 bytes 的處理有「前導代理」(Leading Surrogate)與「後尾代理」(Trail Surrogate)的規則細節。
下篇寫一些在 Code 上面的情況與轉換。
Self Checklist:
- What is
Encoding,Character Encoding,Decoding. - What is Binary, Decimal, Hexadecimal, Octal System.
- What is
ASCII. - What is the difference between
ASCII,Unicode,UCSandUTF. - What is the difference between
Character set,Code PointandEncoding Process.
References:
- 必看:
- 其他:
- http://www.chi2ko.com/tool/CJK.htm
- http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
- http://kevin.hwai.edu.tw/~kevin/material/JAVA/Sample2016/ASCII.htm
- http://utf8everywhere.org/
- https://blog.hubspot.com/website/what-is-utf-8
- https://baike.baidu.com/item/ASCII/309296
- https://www.binary-code.org/binary/8bit/00111001/
- https://www.convertworld.com/zh-hant/numerals/hexadecimal.html
- https://zh.wikipedia.org/wiki/Unicode%E5%AD%97%E7%AC%A6%E5%B9%B3%E9%9D%A2%E6%98%A0%E5%B0%84
- https://www.bilibili.com/video/BV1gZ4y1x7p7?from=search&seid=2657693919162769058&spm_id_from=333.337.0.0
- https://www.zhihu.com/question/302200063
< 下一篇Part2 > [Character set & Encoding]Part1.字元編碼 ASCII, Unicode, UCS, UTF